Тест Знаний для Windows
Версия 1.6, Автор — Анатолий Коваленко
В ЭТОЙ ВЕРСИИ:
* использование списков универсального формата ms-excel или ms-word * использование немецких и других нестандартных букв * таймер * проверка только части слов большого списка * ограничение по времени * прямой или произвольный порядок слов * реверсия перевода * подсказка первой буквы * упрощенное управление при тестировании * подробная статистика * просмотр статистики за любой сеанс тестирования * прохождение повторного теста только по ошибкам * просмотр и печать невыученных слов и их экспорт в буфер обмена или RTF * анализ текстов * совместимость с Win 2k/XP *
Информацию о нововведениях смотрите в приложении 4.
ВНИМАНИЕ: АВТОР НЕ НЕСЕТ ОТВЕТСТВЕННОСТИ ЗА ЛЮБОЙ УЩЕРБ, ПРИЧИНЕННЫЙ ИСПОЛЬЗОВАНИЕМ ИЛИ НЕ ИСПОЛЬЗОВАНИЕМ ЭТОЙ ПРОГРАММЫ. АВТОР ТАКЖЕ НЕ ГАРАНТИРУЕТ, ЧТО ЭТА ПРОГРАММА БУДЕТ РАБОТАТЬ НАДЛЕЖАЩИМ ОБРАЗОМ.
1. Системные требования.
Программа тестировалась на Intel Celeron-1300, Windows 98 и 2003 Server.
Предыдущие версии тестировались на
AMD 486-66, Windows 95.
Intel Pentium-200, Windows 98.
2. Назначение.
Данная программа предназначена для проверки качества запоминания переводов слов или фраз с любого языка на другой. Допускается использовать сколько угодно списков со словами, причем слова могут выводиться как в прямой, так и в произвольной последовательности. Направление перевода можно легко изменить. При желании, время ответа можно ограничивать таймером (от 1 до 99 секунд). В конце проверки выдается подробная статистика с возможностью повторить тест по ошибкам в любое свободное время. Раздел <анализ текстов> поможет подготовить списки наиболее употребительных слов.
3. Установка.
Программа устанавливается самостоятельно. При первом запуске вам сообщат, что запись в реестре не найдена. После того, как вы нажмете «ОК», будет создана новая запись в реестре.
4. Несколько слов об операционных системах.
Собственно, эта версия программы вышла исключительно из-за того, что предыдущая версия <проглатывала> нестандартные буквы немецкого алфавита на Win 2k/XP, хотя на Win 98/ME все работало прекрасно. Причина кроется в том, что Win 95+ использует ANSI, в то время как Win NT+ использует Unicode. Создавая эту версию, мне пришлось переписать немалую часть кода, чтобы обеспечить нормальную работоспособность в Win NT/2k/XP. Вроде даже удалось сохранить совместимость с Win 98/ME. Однако надо помнить, что RTF, сохраненные в одном типе OS не будут правильно читаться в другом. Но особенности нового кода позволяют даже в WIN 2k/XP правильно отображать списки, созданные на Win 98/ME. Все это касается исключительно нестандартных букв. С русским и английским языками нет никаких проблем во всех версиях Windows.
Если вы работаете в Win 2k/XP, но не можете добиться правильного отображения умляутов, внимательно прочитайте этот файл (разделы про патч и новый синтакс списков).
5. Последовательность работы.
a) создание списка слов в MS-Excel, MS-Word или Notepad.
b) выбор файла-списка на закладке «Настройки».
c) переход на закладку «Тест» и прохождение теста.
d) просмотр результатов на закладке «Статистика».
e) заучивание списка невыученных слов.
f) прохождение повторного теста по списку невыученных слов.
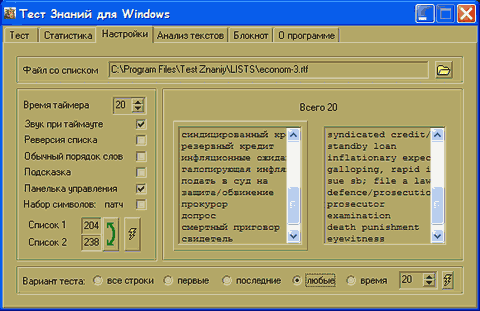
6. Закладка «Настройки».
— Файл со списком:
Из этого файла будет взят список для проведения теста.
— Время таймера:
Этот параметр определяет, через какое количество секунд ваше бездействие сочтут за незнание. Значение «0» отключает таймер, при значениях «1»-«99» таймер включен, и среднее время ответа заносится в статистику.
— Звук при таймауте:
Имеет смысл только при включенном таймере. Данная функция выдает короткий звук, когда время таймера истекает. Сам звук можно установить в «Панель управления->Звук и мультимедиа->Озвучивание событий->Стандартный звук».
— Реверсия списка:
Позволяет изменить направление перевода (например, англо-русский на русско-английский).
— Обычный порядок слов:
Если данная функция включена, слова будут выводиться в той последовательности, в какой они записаны в файле. Иначе используется произвольная последовательность.
— Подсказка:
При выполнении теста показывает первую букву правильного ответа. Имеет мало смысла и вводит в заблуждение, если список подразумевает использование артиклей и других служебных слов перед словами.
— Панелька управления (ПУ):
Обеспечивает максимально удобные условия при управлении тестом с помощью мыши.
— Набор символов:
При переводе с языка, имеющего нестандартные буквы (немецкий, японский, французский), придется указать специальный набор символов, содержащий нужные буквы. Введите соответствующие значения наборов символов для обоих списков. Для русских букв — 204, для английских — 204/238/000, для немецких и многих других — 238. (Все цифры должны быть трехзначными, например, вместо 1 пишем 001. Подробнее о цифровых обозначениях написано в приложении 1). Эти значения можно поменять местами кнопкой с полукруглой стрелкой.
ВНИМАНИЕ: Неправильная установка данного параметра может привести к невозможности прочитать оригинал и перевод. До начала теста можно проверить понятность слов в списках слов в правом нижнем углу вкладки «Настройки». Убедитесь, что в оригинале и переводе видны все буквы. Если один из языков — немецкий, в этих списках нестандартные буквы могут заменяться русскими, но во время теста они будут видны нормально.
ПРИМЕЧАНИЕ: Чтобы избежать ручной настройки наборов символов используйте возможность программы автоматически простанавливать правильные параметры при каждой загрузке данного списка. Смотрите раздел «Создание собственных списков для тестирования».
— Патч для набора символов:
Это крайне ужасная опция. Используется только в Win 2k/XP для файлов с нестандартными символами, написанными в Win 98/ME. Что происходит: во время чтения RTF файла он декодируется не в <родной> кодировке, а в некоторой другой (для русскоязычного населения это 204, для других — подбирается методом эксперимента, возможно 238). После раскодирования, список отображается в том наборе символов, который выбран на закладке <настройки>. Эту внутреннюю кодировку русским пиплам менять не следует, но на случай, если когда-нибудь понадобиться, я сделал к ней доступ через реестр — параметр:
«HKEY_CURRENT_USER\Software\Anatoliy Kovalenko\Test Znaniy\charsetp»
— Списки слов:
Во-первых, вы видите, с какого языка будет производиться перевод во время теста — слова исходного языка обведены рамочкой. Щелкните на любое слово, чтобы синхронизировать списки. Во-вторых, во время выполнения теста в этом окне остаются только те слова, которые еще предстоит перевести.
— Вариант теста:
a) все строки — загружает все строки файла. Используется для маленьких списков.
b) первые X — загружает только указанное количество строк с начала файла. Используется, если вы добавляете новые слова в начло файла и не хотите тратить время на проверку уже выученных слов. В данном случае, параметр X определяет количество новых слов, которые вы дописали.
c) последние X — загружает указанное количество последних строк из файла. Используется как и в b), только здесь вы дописываете новые слова в конец файла.
d) любые X — загружает из файла желаемое количество произвольных слов. Используется для больших списков при нехватке времени проверить все слова, либо для ежедневного «освежения» памяти (X варьируется в зависимости от свободного времени, которое вы желаете потратить на тест).
e) время X — проводит тест по всем словам списка в течении X минут, после чего тест прекращается. Можно использовать обычный или произвольный порядок слов и реверсию (см. выше).
Окошко с числом позволяет ввести параметр X для загрузки строк по выбранному методу. Кнопка с молнией производит повторное чтение файла, чтобы новый параметр вступил в силу.
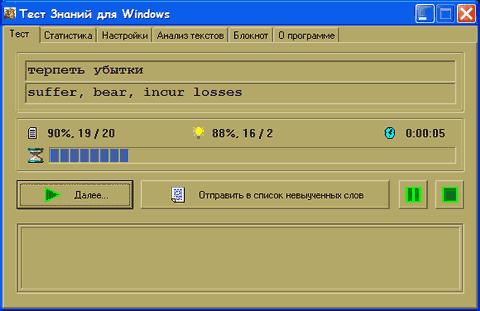
7. Закладка «Тест».
— Начать тест:
Данная кнопка делает то, что на ней написано.
ПРМЕЧАНИЕ: Если показанное предложение не помещается полностью на экране, можно нажать мышью на углубление, в котором находится предложение, и потянуть мышь вправо, не отпуская нажатую кнопку.
— Прервать (кнопка с зеленым квадратом):
Прекратить сеанс тестирования. При этом файл статистики не сохранится.
— Приостановить (кнопка с зеленым значком паузы):
Поскольку «хороший» тест может длиться несколько часов, в программе предусмотрена функция приостановки, чтобы информация о расчетном времени не искажалась, если вы захотите ненадолго отдохнуть от теста. Для входа в режим приостановки, нажимайте на кнопку паузы, когда она зеленая. В других случаях функция паузы отключена. Чтобы вернуться к тесту, нажмите на цветное изображение шимпанзе! Во время теста можно делать сколько угодно пауз. В тесте на время режим паузы приостанавливает таймер оставшихся минут.
В статистике в пункте «Время проверки» будет указано время, которое вы потратили на работу (то есть из времени выполнения теста будет вычтено время всех пауз).
— Показать правильный перевод (Shift или Ctrl, либо нажатие на любою кнопку мыши, когда курсор находится над ПУ):
Если вы вспомнили перевод слова (или если вы понимаете, что все равно его не вспомните), нажмите эту кнопку.
— Далее (Shift или Enter, либо левая кнопка мыши над ПУ):
Если показанный перевод полностью соответствует тому, что вы вспомнили, нажмите эту кнопку.
— Отправить в список невыученных слов (Ctrl, либо правая кнопка мыши над ПУ):
Если вы все же не вспомнили правильный перевод, или вспомнили, но не полностью, нажмите эту кнопку. Если вы пройдете тест до конца, то сможете в любое время посмотреть список невыученных слов и даже пройти тест по этим словам.
ПРИМЕЧАНИЕ: Быстрые клавиши Ctrl и Shift работают, только если фокус (рамочка в виде пунктирной линии) находится на кнопке «Далее».
ПИМЕЧАНИЕ2: Многие присылали мне e-mail с вопросом о том, почему им не удается ввести ответ с клавиатуры в поле перевода. Ничего вводить не надо! Компьютер никогда не решит, знаете вы все варианты перевода одного слова или нет. Это должны решать вы сами, в зависимости от того, насколько вы считаете то или иное слово важным для заучивания. Если вам кажется, что слово вам не понадобится (или если вы его уже знаете), вы просто нажимаете «Далее» и забываете о нем. Если слово нужно выучить, а перевод вспомнить не удалось, тогда вы отправляете его в список невыученных слов, чтобы выучить его позднее.
— Таймер и текущая статистика (обновляется при новом слове):
Таймером является синяя полоска, увеличивающаяся со временем. Как только время истечет, слово отправится в «список невыученных слов».
Список x%,y/z
x — на сколько процентов выполнен тест
y — текущее слово по списку
z — общее количество слов в списке
Лампочка x%,y/z
x — текущий процент знаний
y — количество правильных ответов
z — количество неверных ответов
Часы — ч:мм:сс — расчетное время до окончания теста. Надо сказать, что показания вычисляются исходя из того, что вы тратите приблизительно равное время на обдумывание каждого вопроса. Т.е., если вы пройдете половину теста быстро, а потом устанете и будете отвечать медленно, то данный показатель не будет показывать реальное время, через которое вы закончите. Впрочем, при обычной работе расчетное время обычно близко к реальному.
Если тест проводится на время, то слева от символа часов будет показано реальное время в минутах до окончания теста (конечно, если список не закончиться раньше).
8. Закладка «Статистика».
— Название теста:
Показывает, по какому файлу проводился тест.
— Файл статистики:
Название файла, в который сохранена статистика. Структура названия этого файла такова: первые четыре цифры — месяц и день теста, далее — порядковый номер теста за данный день. (Например, «0125-015» означает, что это статистика за 15-й тест, проведенный 25-го января). Файлы статистики сохраняются в подкаталоге «STATS» и имеют расширение «.STA».
— Открыть:
Позволяет открыть старый файл статистики (для просмотра результатов или для прохождения теста по ошибкам).
— Рука вправо/влево:
Если выбран файл статистики, эти кнопки позволяют быстро передвигаться по всем файлам статистики за выбранный день.
Данная функция используется для быстрого поиска нужной статистики, если вы проходите несколько тестов в день.
ПРИМЕЧАНИЕ: Кнопки с руками не производят перемещение с одной даты на другую — только в пределах одной даты.
— Удалить:
Данная функция позволяет содержать папку с файлами статистики в порядке. Если набралось слишком много ненужных файлов со статистикой, нажмите эту кнопку. Выделите статистики, которые больше не нужны. Используйте стандартные сочетания «Shift-Click» для выделения соседних файлов и «Ctrl-Click» для выделения отдельных файлов, а также «Ctrl-A» для выделения всех файлов. После этого нажмите «Открыть».
— Пройти тест снова:
Эта кнопка позволяет быстро начать тест по списку, к которому относится выбранная статистика.
— Проверить ошибки:
Нажатие этой кнопки приводит к новому тесту по неверно переведенным словам из старого теста, к которому относится выбранная статистика.
ВНИМАНИЕ: при прохождении теста снова и теста по ошибкам используются ТЕКУЩИЕ настройки, а не те, которые были во время теста, к которому относится выбранная статистика. Если направление перевода или вариант теста вас не устраивает, смените настройки.
— Экспортировать список в RTF:
Список невыученных слов можно экспортировать в формат RTF. Файл в этом формате можно прочитать и распечатать в MS-Word или WordPad. Если предполагается, что слова содержат немецкие буквы, то они сохранятся как русские, если их не переконвертировать в unicode, поэтому убедитесь, что соответствующая опция включена. В отличие от RTF, сохраненных из MS-Word в WinME, эти RTF будут читаться правильно и в Win 2k/XP, и в Win ME, вне зависимости от того, в какой OS вы используете Тест Знаний.
— Показать ошибки:
Показывает список слов, которые вы не смогли правильно перевести при прохождении теста, к которому относится выбранная статистика. Направление перевода и наборы символов соответствует тем, которые использовались при тестировании. Для изменения шрифта для показа или печати можно нажать правой кнопкой мыши на любое слово. Имейте ввиду, что не все шрифты имеют русские и немецкие буквы. Двойное нажатие мышью на любое слово столбца приводит к помещению всего столбца в буфер обмена. В появившемся окне вам предложат также распечатать его на принтере.
9. Закладка «Анализ текстов».
Функция анализа текстов позволяет составить список наиболее употребительных слов на основе имеющегося у вас документа. Подходят документы в формате RTF (MS-Word) и обычные текстовые файлы.
ПРИМЕЧАНИЕ: на медленных компьютерах процесс распознавания слов может занять длительное время.
ПРИМЕЧАНИЕ: Ограничение на количество слов в тексте — около 32000 слов. При большем количестве программа не будет работать с исходным текстом. Рекомендация — загрузить первую часть текста в режиме сортировки по количеству, отсеять часто употребительные слова этого текста в отдельный фильтр, загрузить полную версию текста с использованием этого фильтра.
К примеру, помещение в фильтр только слов «and, the, to, a» может увеличить объем входного текста на 4500 дополнительных слов, добавление слов, которые встречаются в тексте больше 100 раз, может увеличить исходный текст еще на 14000 слов, а если отсеять все слова, которые встречаются больше 10 раз, то размер исходного документа можно увеличить в 3-5 раз.
— Открыть файл:
Выберите документ, из которого вы хотите получить слова.
— Сохранить:
Когда работа будет закончена, сохраните результат в текстовый файл. Чтобы доработать этот файл в список для проведения тестов, откройте его в программе MS-Word или Notepad и, нажимая TAB после слова-оригинала, выпишите перевод из словаря. Когда все слова будут сопровождаться переводами, сохраните файл в подкаталог «LISTS».
— Минимальное количество букв:
Здесь следует указать минимальное количество букв, при котором слово не будет игнорироваться. Например, при значении 3, слова «I», «to» и т.п. не попадут в список. Эту функцию полезно использовать для отсеивания широко известных слов или мусора, не указанного в поле «разделители».
— Сохранять слово при количестве от:
В этом поле должно быть указанно минимальное количество повторений для одного слова, чтобы оно попало в список. Например, при значении 3, в список попадут только те слова, которые встречались в тексте три или более раз. Следует иметь ввиду, что слово и его словоформы не считаются как одно слово: move не равно moved, make не равно makes и т.д. Для каждого такого варианта будет собственный счетчик повторений. Большие и малые буквы считаются равными (т.е. «The»=»the»). Чтобы счетчик не влиял на результат, введите «0» в это поле.
— Набор символов:
Определяет, какой набор символов следует использовать при отображении результата (204 — русский, английский; 238 — немецкий). Более подробную информацию смотрите в приложении 1.
— Разделители:
Список символов, которые, как предполагается, находятся между словами. Как правило, для всех текстов следует включать в этот список пробел, запятую, точку, двоеточие, точку с запятой и другие знаки пунктуации. Для более «чистого» результата набор разделителей следует подбирать к каждому конкретному тексту отдельно. Например, используя апостроф, вы делите слово «you’re» на «you» и «re», а, не используя его, строка » He said: ‘Your dog is killing your cat’ » создает два разных счетчика для слов «your» и «‘your». Один из способов не включать в список оторвавшиеся «хвосты» (m от I’m, re от you’re, s от Jack’s и т.д.) — поставить параметр минимальное количество букв на 3.
Если вы поэкспериментировали с этим параметром, и распознавание слов ухудшилось, вы можете вернуть значение по умолчанию, щелкнув дважды в поле строки с разделителями.
ПРИМЕЧАНИЕ: Символ «|» заменяет знак табуляции.
ПРИМЕЧАНИЕ: Чем больше количество разделителей, тем медленнее происходит обработка. Для быстрых машин рекомендуется кроме символов ~@#$%^&*=+[]\/ добавить также все цифры.
— Сортировка по количеству:
При этом параметре слова выводятся в порядке их количества в тексте (те, которых больше, выводятся сверху). Иначе все слова выводятся в алфавитном порядке. На медленных компьютерах процесс сортировки по количеству может занять несколько минут, особенно, если слов много.
— Сохранять количество:
При сохранении результата в файл после каждого слова будет добавляться его количество в тексте после знака табуляции. Эта функция полезна для изучения статистики, например, в программе MS-Excel.
— Фильтр:
Помогает для составления списков из часто встречающихся слов. Поскольку количество хорошо известных слов, таких как «and», «you», «make» и т.п., как правило, велико в любом тексте, их желательно отсеивать автоматически, чтобы они не мешали поиску неизвестных слов. Для этого их следует поместить в файл фильтра и включить функцию «фильтр». Можно создать сколько угодно фильтров для разных пользователей или разных языков. Чтобы создать новый фильтр, нажмите на кнопку с чистым листом и введите имя нового фильтра. Чтобы открыть существующий фильтр, нажмите кнопку с открывающейся папкой. Чтобы поместить слово из списка в файл текущего фильтра, щелкните по нему дважды левой кнопкой мыши. Слово удалится из списка и запишется в конец файла фильтра (если это слово уже есть в фильтре, то оно не будет записано повторно). Можно создать фильтр вручную: создайте текстовый файл, запишите в столбик слова, которые вы хотите удалять из списков, сохраните файл с расширением «.FLT» и скопируйте его в каталог со списками «LISTS».
ПРИМЕЧАНИЕ: Включение больших фильтров сильно замедляет работу.
ПРИМЕЧАНИЕ К ЗАКЛАДКЕ «АНАЛИЗ ТЕКСТОВ»: чтобы новые установки вступили в силу, следует снова открыть файл документа.
10.Закладка «Блокнот».
Сюда можно записать любую информацию, которую вы хотите запомнить. Можно использовать буфер обмена (Ctrl-C — копировать, Ctrl-V — вставить).
11. Закладка «О программе».
Здесь можно узнать версию программы, посмотреть, как связаться со мной, чтобы сообщить об обнаруженных ошибках и пожеланиях, также там написано, где можно скачать новые версии программы.
12. Создание своих списков для тестирования.
Символ-разделитель служит для разделения строки оригинала от строки перевода. Для этих целей может служить любой символ, кроме ‘0’-‘9’. По-умолчанию, для всех поддерживаемых форматов принят символ табуляции (Tab), кроме «.CSV», у которого символом-разделителем служит ‘;’. Данный формат не очень удобен, так как не позволяет использовать точку с запятой в строках оригинала. Поддержка этого формата сохранена в этой версии только для совместимости с уже созданными списками.
Если символ табуляции не может быть использован как символ-разделитель, его можно изменить на другой, указав в первой строке списка знак ‘@’ и желаемый символ, например «@/» для символа ‘/’.
ВАЖНОЕ ЗАМЕЧАНИЕ: В предыдущих версиях символ-разделитель указывался после знака «#». Это актуально и сейчас. Разница вот в чем: если использовать «#», то автоматически включится патч, а если «@», то патч выключится. Таким образом, «#» используется для старых списков, написанных на Win 98/ME, а «@» используется для списков, которые вы будете сохранять в Win 2k/XP.
ВНИМАНИЕ: Если одна из строк не содержит символа-разделителя, она просто будет пропущена при загрузке (без всякого сообщения об ошибке). Отсутствие указания на символ-разделитель в первой строке подразумевает, что используется знак ‘;’ для «.CSV» и Tab для остальных форматов.
Примеры правильно созданных списков:
==== (1) символ — Tab, любой формат кроме «.CSV»
close закрывать; близкий
good польза; хороший
==== (2) символ — ‘;’, формат — только «.CSV»
проверка;test
рыба;fish
==== (3) символ — ‘;’, любой формат
@;
word;слово
to see;видеть
====
Создание списка в MS-Excel.
Этот метод имеет один недостаток — проблема ввода немецких и других нестандартных символов, однако для англо-русских списков он подходит. Список делают так: создают новую таблицу, в первом столбце пишут слово, во втором — перевод. Потом все это сохраняется в формат «.TXT» (Файл->Сохранить как->Тип файла->Текстовые файлы с разделителями табуляции *.txt). Сохраните файл в подкаталог «LISTS», находящийся в каталоге, в который вы установили программу. Этот список можно будет продолжать в дальнейшем.
Создание списка в MS-Word.
Этот метод удобен для ввода букв, не имеющихся на клавиатуре, например, некоторых букв немецкого языка. Вы можете вводить немецкие и другие буквы стандартным способом, предусмотренным MS-Word, однако значительно проще будет воспользоваться такими комбинациями:
alt-s, alt-u (o,a), alt-shift-u (o,a) — соответствующие буквы с умляутом. (Назначения для других языков делайте в Вставка->Символ->Клавиша). Для инициализации таких последовательностей перепишите файл «deutsch.dot» в каталог шаблонов (например, c:\program files\microsoft office\шаблоны). В меню Файл->Создать выберите «deutsch.dot» и создавайте свой список. Другой вариант — создать новый документ, Сервис->Шаблоны и надстройки->Присоеденить->»deutsch.dot». Пример использования MS-Word для создания списка с немецкими буквами смотрите в «LISTS\german.rtf»
ПРИМЕЧАНИЕ: для придания своим спискам приличного вида (с двумя столбцами), установите в Формат->Табуляция->По умолчанию 7 см.
После создания списка сохраните его в подкаталоге «LISTS» в формате «.RTF» (Не DOC!). Список можно будет продолжать.
Создание списка в Блокноте (Notepad).
Используется при отсутствии MS-Word и MS-Excel. Работа в данном случае аналогична работе в MS-Word, только нестандартные буквы вам не будут доступны. В конце работы сохраните файл с расширением «.TXT».
Указание набора символов для автоматической установки параметров при загрузке списка.
Для автоматической простановки наборов символов оригинала и перевода просто укажите соответствующие трехзначные номера после знака-разделителя в первой строке, например:
==== (1) оригинал — русский, перевод — немецкий, «.RTF»
@~204238
книга~das Buch,Buch(e)s,Buecher
==== (2) наоборот, разделитель — Tab, «.RTF»
@238204
das Buch,Buch(e)s,Buecher книга
====
ПРИМЕЧАНИЕ: как видно в примере, если в списке используется символ-разделитель по-умолчанию, то его можно вообще не указывать. К примеру, для англо-русского списка вполне можно не указывать ни знак-разделитель, ни наборы символов:
==== CSV, настройка отключена, разделитель — ‘;’
a table;стол
to run;бежать
====
Если в списке с нестандартными буквами не указаны соответствующие наборы символов и состояние патча, то их придется устанавливать вручную после каждой загрузки списка. Если они указаны, но их изменение из программы Тест Знаний не будет иметь никакого эффекта.
13. Печать списка (Это старый метод. Лучше используйте экспорт в RTF).
A) Если вы работаете в MS-Excel — просто выровните ширину столбцов и печатайте как обычно.
B) При работе в MS-Word, если знак-разделитель не Tab, проделайте следующее: Правка->Заменить, «знак-разделитель» на «^t», для всех. Данное действие заменяет все знаки-разделители на Tab. Имея список, где оригинал и перевод разделены Tab’ом, отрегулируйте шаг табуляции в «Формат->Табуляция» так, чтобы оригиналы не залезали на столбец с переводами.
Либо можно переместить данные в Ms-Excel: В документе MS-Word с Tab’ами нажмите Ctrl-A, Ctrl-C, создайте новую книгу MS-Excel и нажмите в ней Ctrl-V. Вы получите таблицу, в одном столбце которой будут оригиналы, в другом — переводы. Далее переходите к пункту A).
ПЕЧАТЬ СПИСКА НЕВЫУЧЕННЫХ СЛОВ.
Списки невыученных слов хранятся в подкаталоге STATS вместе с файлами статистики. Более того, они имеют аналогичные названия. Имея статистику 0315-002, можно найти список слов к ней в файле «STATS\0315-002.TXT». MS-Excel выберите «Открыть->Тип файлов->Текстовые файлы», выберите нужный файл, в открывшемся мастере текстов выберите «с разделителями», «начать импорт со строки 2», «Далее», символом-разделителем является:» (если Tab — то «символ табуляции», иначе — «другой», и укажите какой именно), «Ограничитель строк — нет», «Готово».
ПРИМЕЧАНИЕ: данный метод НЕ ПОЗВОЛЯЕТ печатать символы немецкого языка. Они будут видны только при печати из программы «Тест Знаний».
ПЕЧАТЬ СПИСКА ДЛЯ САМОПРОВЕРКИ.
Для этого в окне списка невыученных слов выберите желаемый шрифт, после чего распечатайте первый столбец (как — см. раздел «Закладка Статистика, показать ошибки»). Рядом с каждым словом оригинала напишите (ручкой, карандашом) свой вариант перевода. После этого напечатайте второй столбец. Положите распечатку со вторым столбцом рядом с первым листом. В результате, ваши варианты перевода будут находиться напротив правильных переводов. Сравните их и сделайте выводы, какие из слов следует учить:
ПРИЛОЖЕНИЕ 1: НАБОРЫ СИМВОЛОВ.
000 ANSI characters.
001 Font is chosen based solely on Name and Size. If the described font is not available on the system, Windows will substitute another font.
002 Standard symbol set.
077 Macintosh characters. Not available on NT 3.51.
128 Japanese shift-jis characters.
129 Korean characters (Wansung).
130 Korean characters (Johab). Not available on NT 3.51
134 Simplified Chinese characters (mainland china).
136 Traditional Chinese characters (taiwanese).
161 Greek characters. Not available on NT 3.51.
162 Turkish characters. Not available on NT 3.51
163 Vietnamese characters. Not available on NT 3.51.
177 Hebrew characters. Not available on NT 3.51
178 Arabic characters. Not available on NT 3.51
186 Baltic characters. Not available on NT 3.51.
204 Cyrillic characters. Not available on NT 3.51.
222 Thai characters. Not available on NT 3.51
238 Includes diacritical marks for eastern european countries. Not available on NT 3.51.
255 Depends on the codepage of the operating system.
ПРИЛОЖЕНИЕ 2: ВВОД СИМВОЛОВ НАЦИОНАЛЬНЫХ АЛФАВИТОВ.
ПРИЛОЖЕНИЕ 3: Файлы дистрибутива.
ПРИЛОЖЕНИЕ 4: Нововведения.
Что нового в версии 1.5
1) Программа переделана под Win 2k/XP, теперь немецкие умляуты видны. Они также видны в Win 98/ME, если список набирался в такой же OS.
2) Добавлена панелька управления.
3) Исправлены недочеты с растягиванием изображений при высоком разрешении экрана.
4) Убрана встроенная помощь 😉
5) Убрано встроенное удаление программы и чистка реестра. Теперь этим занимается Wise InstallMaster.
Что нового в версии 1.4
1) Добавлена функция анализа текстов — смотрите помощь о закладке «Анализ текстов».
2) Возможность автоматической деинсталляции программы — смотрите помощь о закладке «О программе».
3) Автоматическое создание ярлыков программы при инсталляции.
4) Возможность приостанавливать тест — при использовании режима паузы из времени всей проверки будет вычитаться время паузы, что позволяет более точно определять время до окончания проверки — смотрите помощь о закладке «Тест».
5) Добавлены рисунки на кнопках.
6) В закладке «настройка» улучшена работа «окошка со списком слов». Можно дважды щелкнуть по любому слову, чтобы увидеть его перевод.
7) Добавлена заставка и иконка с шимпанзе + некоторые мелкие доработки.
Что нового в версии 1.3
1) Помощь теперь встроена в программу, хотя есть возможность читать этот файл в MS-Word (test.doc).
2) Названия файлов статистики заменены — теперь первые две цифры — месяц, другие две — день, остальные — порядковый номер. Это позволяет при открытии файла статистики быстро найти нужный, так как теперь они отсортированы в порядке их создания.
3) Добавлено ограничение на продолжительность теста. Эта функция схожа с функцией загрузки некоторого количества произвольных строк, только там решающим параметром было количество вопросов, на которые надо ответить, а здесь — количество времени, которое вы желаете потратить на тест.
4) Появилась подсказка, то есть при установке данного параметра программа будет подсказывать первую букву ответа. Например, «КОШКА» -> «C:» (Ответ «CAT»).
5) Теперь статистика будет сохранена, даже если вы прервете тест. При этом в пункте «вариант теста» будет приписка «ПРЕРВАН».
6) В закладке «настройка» улучшена работа «окошка со списком слов». Можно указать на любое слово и щелкнуть «реверсия», чтобы увидеть его перевод.
7) Добавлена проверка на «вторичный» запуск.
8) Была произведена проверка программы в Windows 2000. Обнаруженные недостатки были устранены.
9) Значительно расширен список немецких слов.
Внимание: важные изменения!
Версия 1.2 и более поздние.
Если вы использовали более старую версию программы (1.0, 1.1), то:
1) Первую строку некоторые старых списков следует модифицировать согласно этому описанию.
2) Старые файлы статистики больше не поддерживаются — удалите «STATS\*.*»
3) В реестре удалите «HKEY_CURRENT_USER\Software\Тест Знаний» — данная запись больше не будет использоваться новой версией программы.